
Construcción de Aplicaciones RAG con Databricks y Mosaic AI
- Juan Diaz
- 24 Apr, 2025
- 05 Mins de lectura
- Databricks
La Inteligencia Artificial Generativa está transformando la forma en que las empresas interactúan con sus datos y construyen aplicaciones inteligentes. En este artículo, profundizamos en estrategias prácticas para crear soluciones poderosas de IA generativa utilizando las herramientas nativas de Databricks. Exploraremos cómo aprovechar Mosaic AI, implementar Generación Aumentada por Recuperación (RAG) y evaluar el rendimiento del modelo para pasar del concepto a flujos de trabajo listos para producción.
Construcción de Aplicaciones de IA Generativa en Databricks
Databricks ofrece una plataforma unificada para construir y desplegar aplicaciones de IA generativa a escala. Con Mosaic AI y soporte nativo para modelos base, puedes pasar del concepto a producción utilizando tus propios datos.
Patrones para Aplicaciones de IA Generativa
Databricks distingue dos patrones principales de desarrollo:
-
Patrón Monolítico de Prompts: Envías un prompt cuidadosamente diseñado a un modelo de lenguaje grande (LLM) y recibes una respuesta. Esto es útil para tareas simples como resumir, reformular o preguntas y respuestas básicas.
Ejemplo:
Resume el siguiente cuaderno de Databricks sobre optimización de Delta Lake.
-
Patrón Basado en Agentes: Un sistema más avanzado donde un agente coordina múltiples herramientas, como un LLM, un recuperador y un ejecutor de herramientas, para completar tareas de múltiples pasos. Esto es adecuado para aplicaciones más dinámicas e interactivas, como copilotos de IA o agentes autónomos de datos.
Ejemplo:
Un usuario pregunta, “Genera un informe de ingresos para el último trimestre.” El sistema recupera las tablas adecuadas, construye consultas SQL y usa el LLM para narrar los resultados.
Estos patrones pueden implementarse directamente en cuadernos utilizando LangChain, LlamaIndex o Semantic Kernel, todos los cuales son compatibles con Databricks.
¿Qué es Mosaic AI?
Mosaic AI es la solución de Databricks para construir y desplegar aplicaciones de IA generativa listas para producción a escala. Proporciona un conjunto completo de herramientas para trabajar con modelos base, implementar generación aumentada por recuperación (RAG) y gestionar operaciones con modelos de lenguaje grande (LLMOps).
¿Por qué es importante Mosaic AI?
Las plataformas tradicionales de ML no fueron diseñadas para las necesidades únicas de la IA generativa, como manejar datos no estructurados, integrarse con modelos base o gestionar la iteración continua sobre prompts y comportamientos del modelo. Mosaic AI llena ese vacío ofreciendo:
- Integración fluida con marcos de trabajo de código abierto como LangChain y LlamaIndex.
- Soporte nativo para modelos base como LLaMA 2 y MPT, incluyendo afinación de modelos.
- Herramientas específicas para observabilidad y evaluación para rastrear el rendimiento de LLM.
- Características de seguridad y gobernanza para ayudar a las empresas a desplegar de manera responsable.
Ejemplo: Flujo de Trabajo Completo con Mosaic AI
Supongamos que deseas construir un chatbot de soporte utilizando la documentación interna de tu empresa. Así es como Mosaic AI te apoyaría:
- Ingesta de datos no estructurados utilizando cuadernos y pipelines de Databricks.
- Incorporación y almacenamiento de documentos en un almacén de vectores.
- Uso de LangChain o LlamaIndex para conectar el LLM con tu base de conocimiento (patrón RAG).
- Despliegue de la aplicación a través de una API o una aplicación Streamlit.
- Monitoreo de las respuestas del modelo utilizando las herramientas de evaluación de Mosaic AI.
Componentes Clave
Mosaic AI está compuesto por varios componentes estrechamente integrados diseñados para soportar todo el ciclo de vida del desarrollo de aplicaciones de IA generativa:
- Mosaic AI Training: Afinación de modelos base (por ejemplo, MPT, LLaMA 2) utilizando métodos eficientes en parámetros como LoRA.
- Mosaic AI Model Serving: Servicio de modelos en tiempo real o por lotes a través de APIs REST.
- Mosaic AI Gateway: Interfaz unificada para dirigir prompts a múltiples modelos (internos o de terceros).
- Mosaic AI Evaluation: Herramientas integradas para monitorear la calidad de salida y el comportamiento del modelo.
Ejemplo: Automatizando el Soporte de Base de Conocimiento
Imagina que una empresa quiere crear un asistente inteligente para responder preguntas de soporte:
- Entrenar un modelo con registros de chats de soporte utilizando Mosaic AI Training.
- Incorporar manuales de productos y documentos en un almacén de vectores.
- Conectar el modelo a esos documentos mediante LangChain o LlamaIndex (RAG).
- Servir el asistente con Mosaic AI Model Serving.
- Monitorear las respuestas con Mosaic AI Evaluation para detectar alucinaciones o contenido irrelevante.
Introducción a RAG
La Generación Aumentada por Recuperación (RAG) conecta los LLMs a bases de conocimiento externas para fundamentar sus respuestas en datos reales. Reduce significativamente las alucinaciones y mejora la calidad de las respuestas en contextos empresariales.
En otras palabras, un RAG es un patrón poderoso que mejora las capacidades de los modelos de lenguaje grande (LLMs) conectándolos a fuentes de datos externas. En lugar de depender únicamente de lo que el modelo aprendió durante su entrenamiento, RAG le permite recuperar información relevante de documentos estructurados o no estructurados en tiempo real, mejorando la precisión factual y reduciendo las alucinaciones.
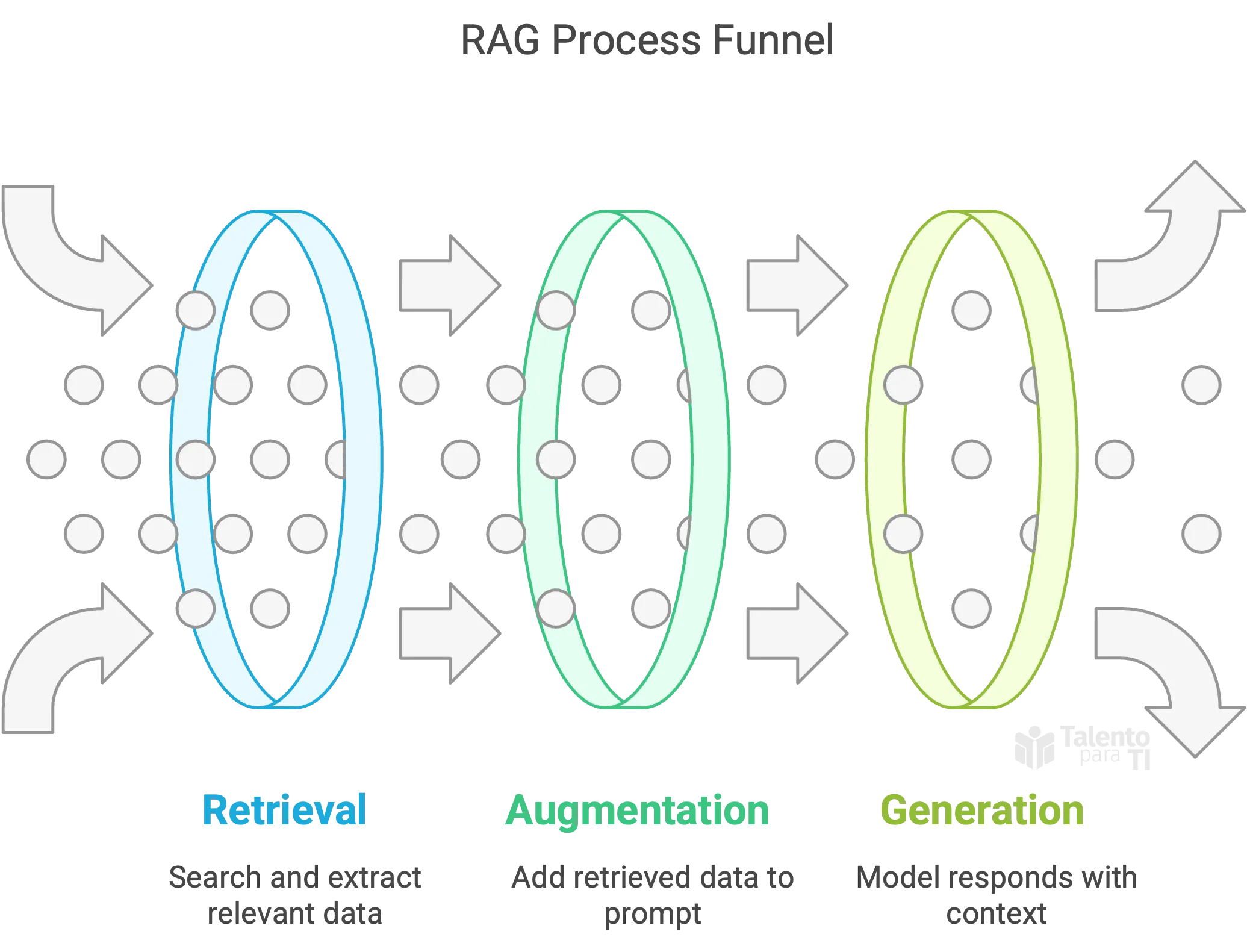
¿Por qué RAG?
Los LLMs están limitados por lo que fueron entrenados. RAG te permite suplementarlos con contenido fresco y específico de dominio en tiempo real.
- Recuperación: Buscar contenido empresarial (PDFs, páginas de wiki, tablas Delta).
- Augmentación: Agregar fragmentos recuperados al prompt.
- Generación: El modelo responde basándose en esta nueva entrada rica en contexto.
Este enfoque híbrido ayuda a ofrecer respuestas más fundamentadas y conscientes del contexto.
Casos de Uso Comunes para RAG
- Soporte al Cliente: Usa tu propia documentación para responder preguntas de clientes.
- Legal y Cumplimiento: Consulta políticas internas o documentos legales con contexto actualizado.
- Asistentes Internos: Ayuda a los empleados a interactuar con sistemas de conocimiento internos.
- Salud y Ciencias de la Vida: Accede a literatura médica y estudios estructurados.
- Finanzas: Automatiza el análisis de documentos y preguntas contextuales sobre estados financieros, contratos y más.
Mejores Prácticas para la Implementación de RAG
- Preprocesa contenido para eliminar datos irrelevantes y fragmentar inteligentemente.
- Elige el modelo de incrustación adecuado (OpenAI, BGE, etc.) según tu dominio.
- Usa bases de datos de vectores (FAISS, Chroma) para almacenar incrustaciones y metadatos.
- Recupera inteligentemente puntuando la relevancia y filtrando datos ruidosos.
- Usa plantillas de prompt claras separando contexto y preguntas.
Todos estos elementos pueden ser orquestados en cuadernos o pipelines utilizando Databricks y marcos como LangChain.
Evaluación y Mejora de Aplicaciones RAG
Databricks soporta la evaluación automatizada y manual de sistemas RAG:
- Puntuación de Relevancia: ¿El contexto recuperado coincidió realmente con la consulta?
- Fundamentación: ¿La respuesta del modelo se basa solo en lo que se recuperó?
- Calidad de Respuesta: Evalúa fluidez, tono, completitud y factualidad.
- Herramientas de Monitoreo: Usa Mosaic AI Evaluation o herramientas de terceros como TruLens, RAGAS, o tus propios métricas.
Consejo: La ingeniería de prompts, estrategias de fragmentación, filtros de recuperación y rerankers afectan el rendimiento final; itera con frecuencia.
RAG en Databricks
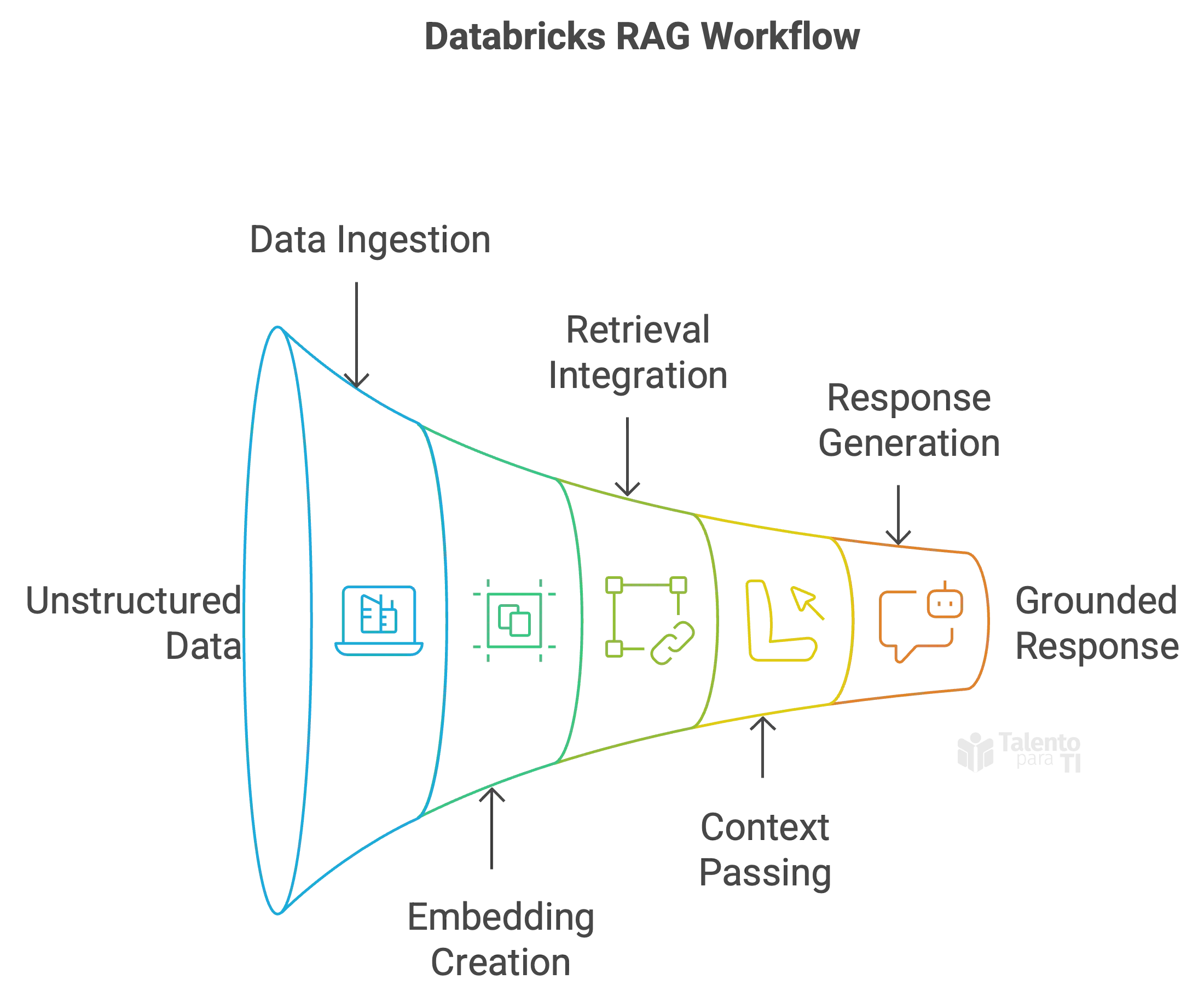
Databricks ofrece un entorno robusto y escalable para implementar flujos de trabajo RAG utilizando herramientas familiares:
- Ingesta y preprocesamiento de datos no estructurados (por ejemplo, manuales de productos, tickets de soporte, publicaciones de blog) utilizando cuadernos y pipelines Delta.
- Incorporación e indexación de datos en un almacén de vectores utilizando modelos como BGE o incrustaciones de OpenAI.
- Integración con marcos de recuperación como LangChain o LlamaIndex para construir el pipeline de recuperación.
- Pasa el contexto al LLM (por ejemplo, MPT, LLaMA 2) junto con el prompt del usuario para generar una respuesta fundamentada en los datos empresariales.
Ejemplo de Flujo de Trabajo: Sistema RAG Potenciado por Databricks
- Usa un cuaderno para cargar documentación interna en PDF.
- Fragmenta y limpia los datos de texto utilizando utilidades de LangChain.
- Genera incrustaciones utilizando un modelo soportado (OpenAI, Hugging Face, etc.).
- Almacena las incrustaciones en una base de datos de vectores (por ejemplo, FAISS, Chroma).
- Crea una cadena de recuperación que busque fragmentos relevantes en respuesta a una consulta.
- Pasa el contexto recuperado y el prompt original a un LLM a través de Databricks Model Serving o API externa.
- Muestra la respuesta fundamentada y rica en contexto en un chatbot o aplicación.
Beneficios de RAG en la Empresa
- Aumenta la precisión de las salidas de los LLM al fundamentarlas en datos actuales y verificados.
- Reduce el riesgo de respuestas alucinadas o desactualizadas.
- Mantiene los datos sensibles privados al controlar el contenido fuente.
- Permite respuestas dinámicas incluso con modelos más pequeños y afinados.
Con Databricks, todas las etapas de la arquitectura RAG, desde la ingestión y recuperación hasta la generación y evaluación, pueden desarrollarse y desplegarse dentro de una plataforma segura y unificada.