
Building RAG Applications with Databricks and Mosaic AI
- Juan Diaz
- 24 Apr, 2025
- 05 Mins de lectura
- Databricks
Generative AI is transforming how businesses interact with their data and build intelligent applications. In this post, we dive into practical strategies for creating powerful generative AI solutions using Databricks’ native tools. We’ll explore how to leverage Mosaic AI, implement Retrieval-Augmented Generation (RAG), and evaluate model performance to move from concept to production-ready workflows.
Building Generative AI Applications in Databricks
Databricks provides a unified platform to build and deploy generative AI apps at scale. With Mosaic AI and native support for foundation models, you can go from concept to production using your own data.
Patterns for Generative AI Apps
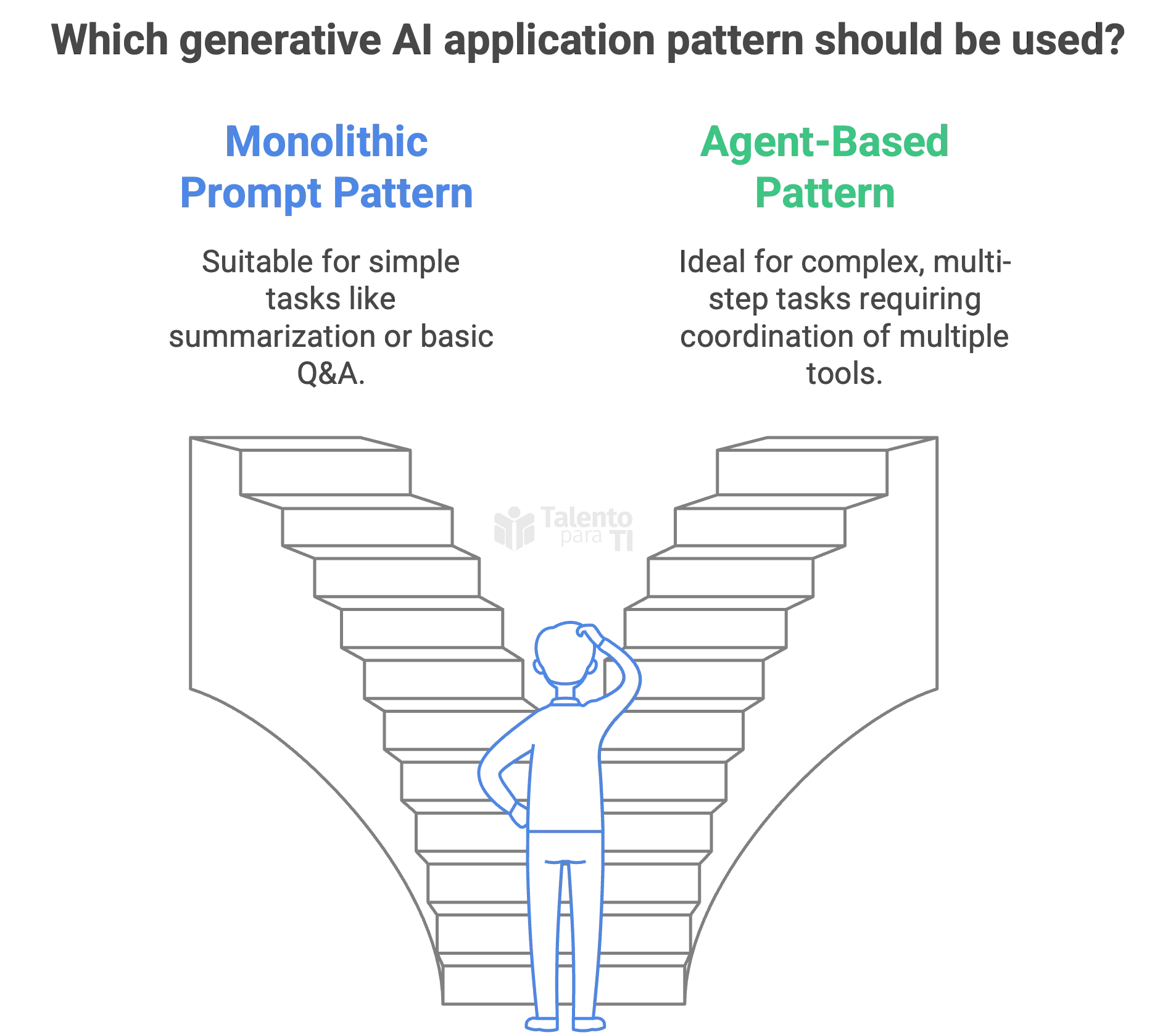
Databricks distinguishes two major development patterns:
-
Monolithic Prompt Pattern: You send a carefully engineered prompt to a large language model (LLM) and receive a response. This is useful for simple tasks like summarization, rephrasing, or basic Q&A.
Example:
Summarize the following Databricks notebook on Delta Lake optimization.
-
Agent-Based Pattern: A more advanced system where an agent coordinates multiple tools—like a LLM, a retriever, and a tool executor—to complete multi-step tasks. This is suitable for more dynamic and interactive applications, such as AI copilots or autonomous data agents.
Example:
A user asks, “Generate a revenue report for the last quarter.” The system retrieves the right tables, builds SQL queries, and uses the LLM to narrate the findings.
These patterns can be implemented directly in notebooks using LangChain, LlamaIndex, or Semantic Kernel, all of which are supported in Databricks.
What is Mosaic AI?
Mosaic AI is Databricks’ solution for building and deploying production-ready generative AI applications at scale. It provides a complete suite of tools for working with foundation models, implementing retrieval-augmented generation (RAG), and managing large language model operations (LLMOps).
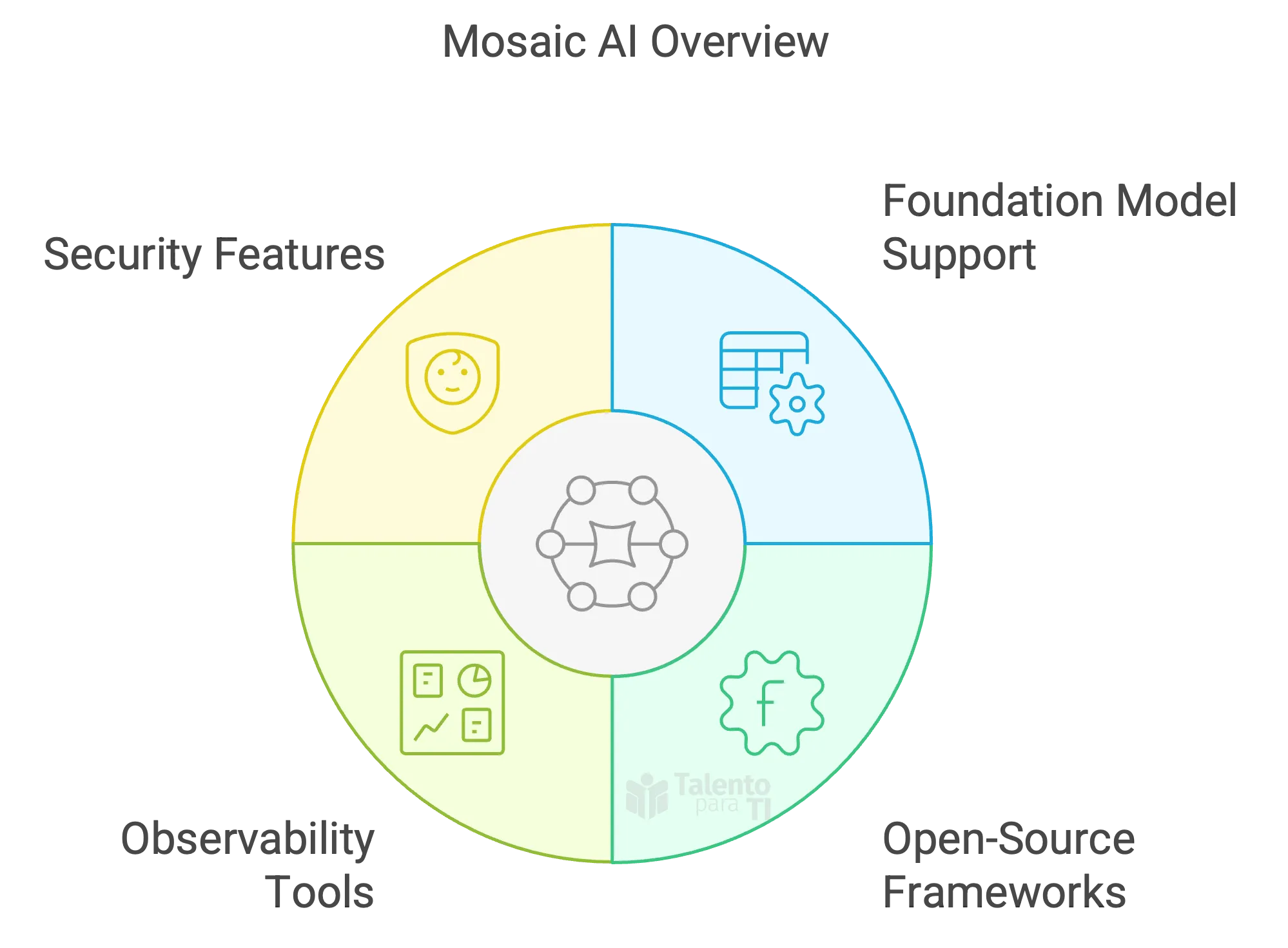
Why Mosaic AI matters
Traditional ML platforms weren’t designed for the unique needs of generative AI—such as handling unstructured data, integrating with foundation models, or managing continuous iteration on prompts and model behavior. Mosaic AI bridges that gap by offering:
- Seamless integration with open-source frameworks like LangChain and LlamaIndex.
- Native support for foundation models like LLaMA 2 and MPT, including model fine-tuning.
- Purpose-built observability and evaluation tools for tracking LLM performance.
- Security and governance features to help enterprises deploy responsibly.
Example: End-to-End Workflow with Mosaic AI
Suppose you want to build a support chatbot using your company’s internal documentation. Here’s how Mosaic AI would support you:
- Ingest unstructured data using Databricks notebooks and pipelines.
- Embed and store documents in a vector store.
- Use LangChain or LlamaIndex to connect the LLM with your knowledge base (RAG pattern).
- Deploy the application via an API or Streamlit app.
- Monitor the model’s responses using Mosaic AI Evaluation tools.
Key Components
Mosaic AI is made up of several tightly integrated components designed to support the full development lifecycle of generative AI applications:
- Mosaic AI Training: Fine-tune foundation models (e.g. MPT, LLaMA 2) using parameter-efficient methods like LoRA.
- Mosaic AI Model Serving: Serve models in real time or batch via REST APIs.
- Mosaic AI Gateway: Unified interface to route prompts to multiple models (internal or third-party).
- Mosaic AI Evaluation: Built-in tools to monitor output quality and model behavior.
Example: Automating Knowledge Base Support
Imagine a company wants to create a smart assistant to answer support questions:
- Train a model with support chat logs using Mosaic AI Training.
- Embed product manuals and documents into a vector store.
- Connect the model to those documents via LangChain or LlamaIndex (RAG).
- Serve the assistant with Mosaic AI Model Serving.
- Monitor responses with Mosaic AI Evaluation to detect hallucinations or irrelevant content.
Introduction to RAG
Retrieval-Augmented Generation (RAG) connects LLMs to external knowledge bases to ground their responses in real data. It significantly reduces hallucinations and improves the quality of answers in enterprise contexts.
In other words, a RAG is a powerful pattern that enhances the capabilities of large language models (LLMs) by connecting them to external data sources. Instead of relying solely on what the model learned during training, RAG enables it to retrieve relevant information from structured or unstructured documents at runtime, improving factual accuracy and reducing hallucinations.
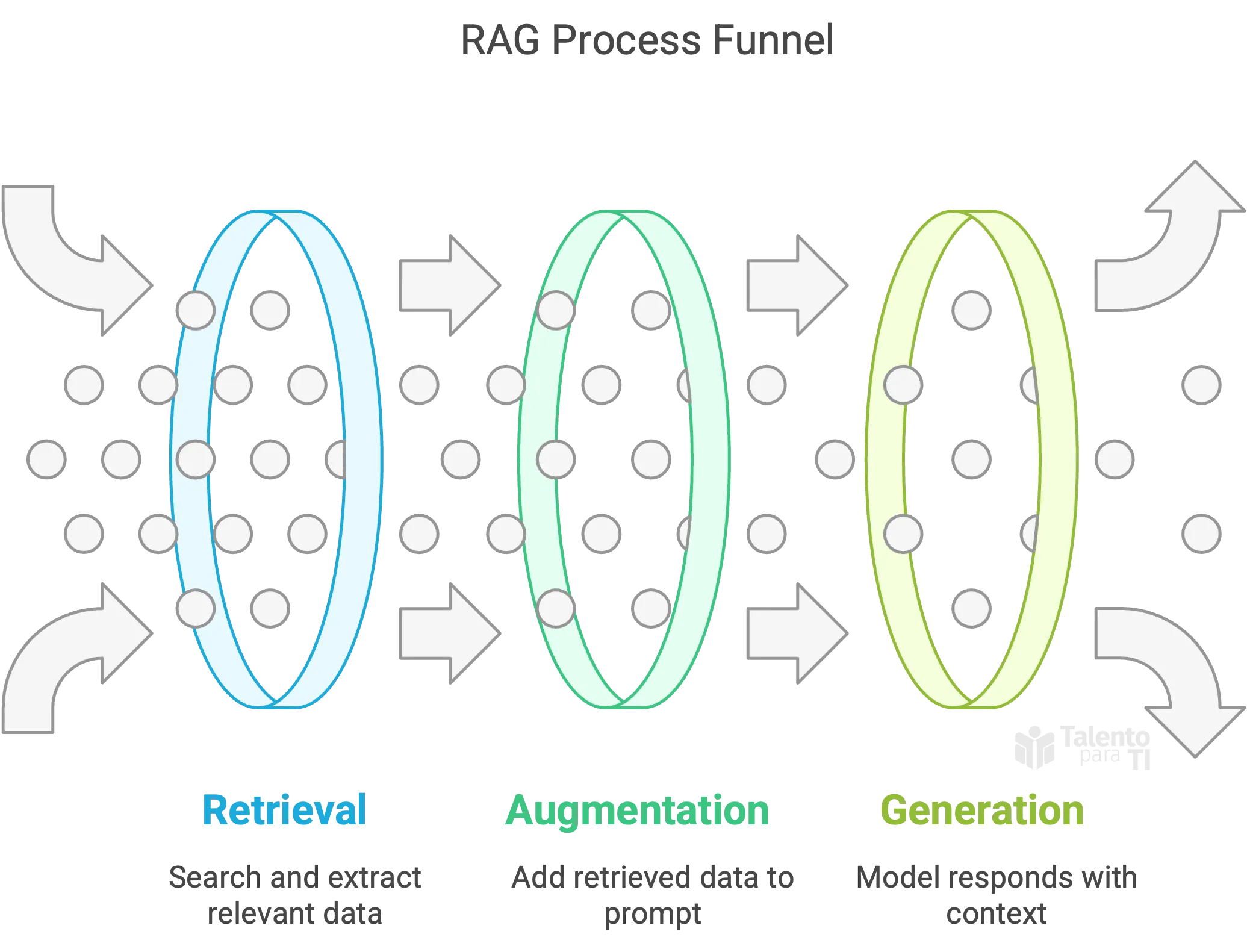
Why RAG?
LLMs are limited by what they were trained on. RAG lets you supplement them with fresh, domain-specific content in real time.
- Retrieval: Search enterprise content (PDFs, wiki pages, Delta tables).
- Augmentation: Add retrieved chunks into the prompt.
- Generation: Model responds based on this new, context-rich input.
This hybrid approach helps deliver more grounded and context-aware responses.
Common Use Cases for RAG
- Customer Support: Use your own documentation to respond to client questions.
- Legal and Compliance: Query internal policies or legal documents with up-to-date context.
- Internal Assistants: Help employees interact with internal knowledge systems.
- Healthcare and Life Sciences: Access medical literature and structured studies.
- Finance: Automate document parsing and contextual Q&A on statements, contracts, and more.
RAG Implementation Best Practices
- Preprocess content to remove irrelevant data and chunk intelligently.
- Choose the right embedding model (OpenAI, BGE, etc.) based on your domain.
- Use vector databases (FAISS, Chroma) to store embeddings and metadata.
- Retrieve intelligently by scoring relevance and filtering noisy data.
- Use clear prompt templates separating context and questions.
All these pieces can be orchestrated in notebooks or pipelines using Databricks and frameworks like LangChain.
Evaluating and Improving RAG Applications
Databricks supports automated and manual evaluation of RAG systems:
- Relevance Scoring: Did the retrieved context actually match the query?
- Groundedness: Is the model’s answer based only on what was retrieved?
- Response Quality: Evaluate fluency, tone, completeness, and factuality.
- Monitoring Tools: Use Mosaic AI Evaluation or 3rd-party tools like TruLens, RAGAS, or your own metrics.
Tip: Prompt engineering, chunking strategies, retrieval filters, and rerankers all affect final performance — iterate often.
RAG in Databricks
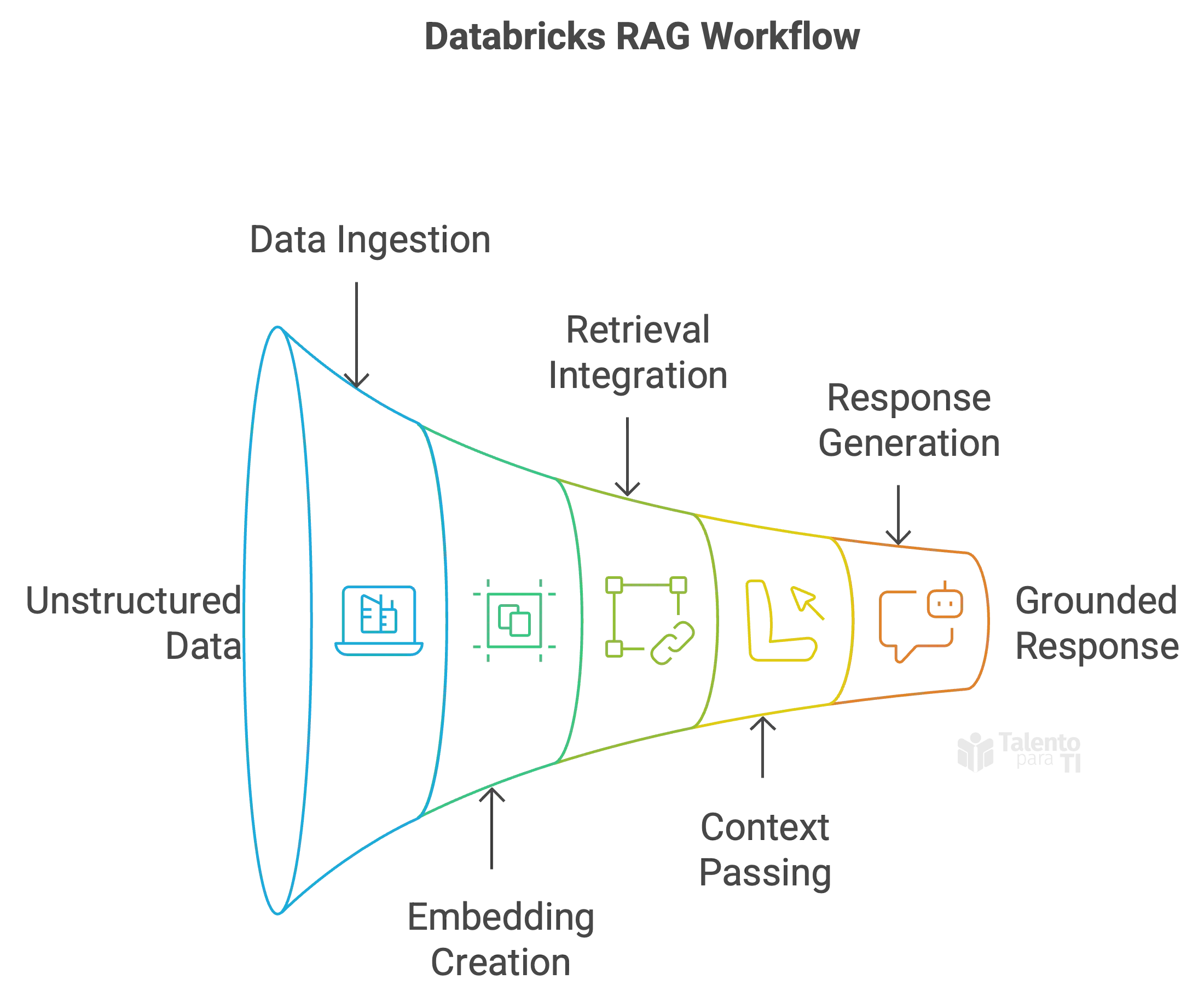
Databricks provides a robust and scalable environment to implement RAG workflows using familiar tools:
- Ingest and preprocess unstructured data (e.g., product manuals, support tickets, blog posts) using notebooks and Delta pipelines.
- Embed and index the data in a vector store using models like BGE or OpenAI embeddings.
- Integrate with retrieval frameworks such as LangChain or LlamaIndex to build the retrieval pipeline.
- Pass context to the LLM (e.g., MPT, LLaMA 2) along with the user prompt to generate a response grounded in enterprise data.
Example Workflow: Databricks-Powered RAG System
- Use a notebook to load internal PDF documentation.
- Chunk and clean the text data using LangChain utilities.
- Generate embeddings using a supported model (OpenAI, Hugging Face, etc.).
- Store the embeddings in a vector database (e.g., FAISS, Chroma).
- Create a retrieval chain that searches for relevant chunks in response to a query.
- Pass retrieved context and the original prompt to an LLM via Databricks Model Serving or external API.
- Display the grounded, context-rich response in a chatbot or app.
Benefits of RAG in the Enterprise
- Boosts accuracy of LLM outputs by grounding them in current, verified data.
- Reduces risks of hallucinated or outdated responses.
- Keeps sensitive data private by controlling the source content.
- Enables dynamic responses even with smaller, fine-tuned models.
With Databricks, all stages of the RAG architecture—from ingestion and retrieval to generation and evaluation—can be developed and deployed within a secure, unified platform.